10. 动作值
动作值
在上一部分,你自己实现了迭代策略评估,以估算策略 \pi 的状态值函数 v_\pi。在此部分,你将使用视频中的简单网格世界练习将状态值函数 v_\pi 转换为动作值函数 q_\pi。
思考下我们用来表示迭代策略评估的小网格世界。等概率随机策略的状态值函数可视化结果如下。
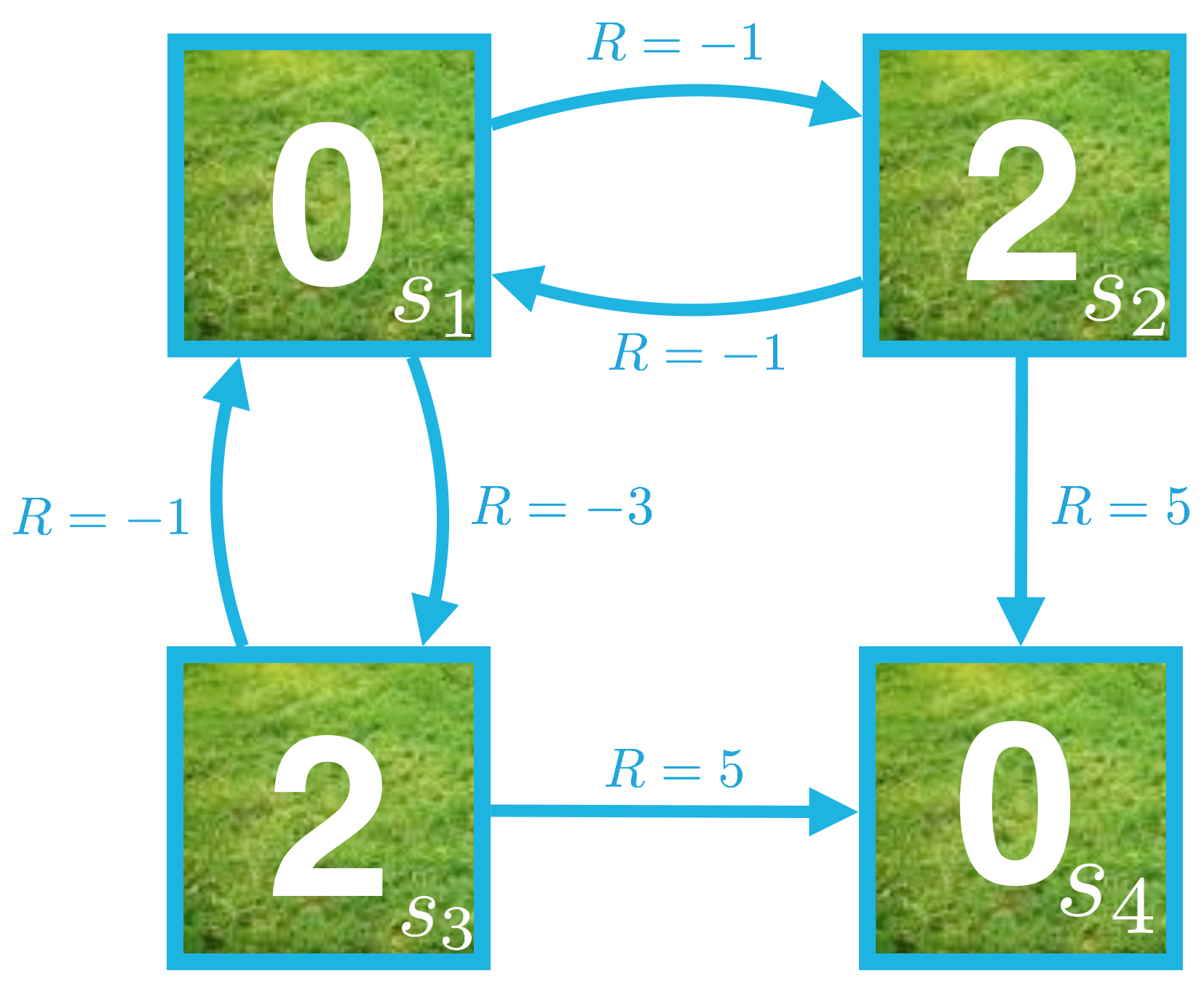
现在花时间确认以下图片对应的是同一策略的动作值函数。
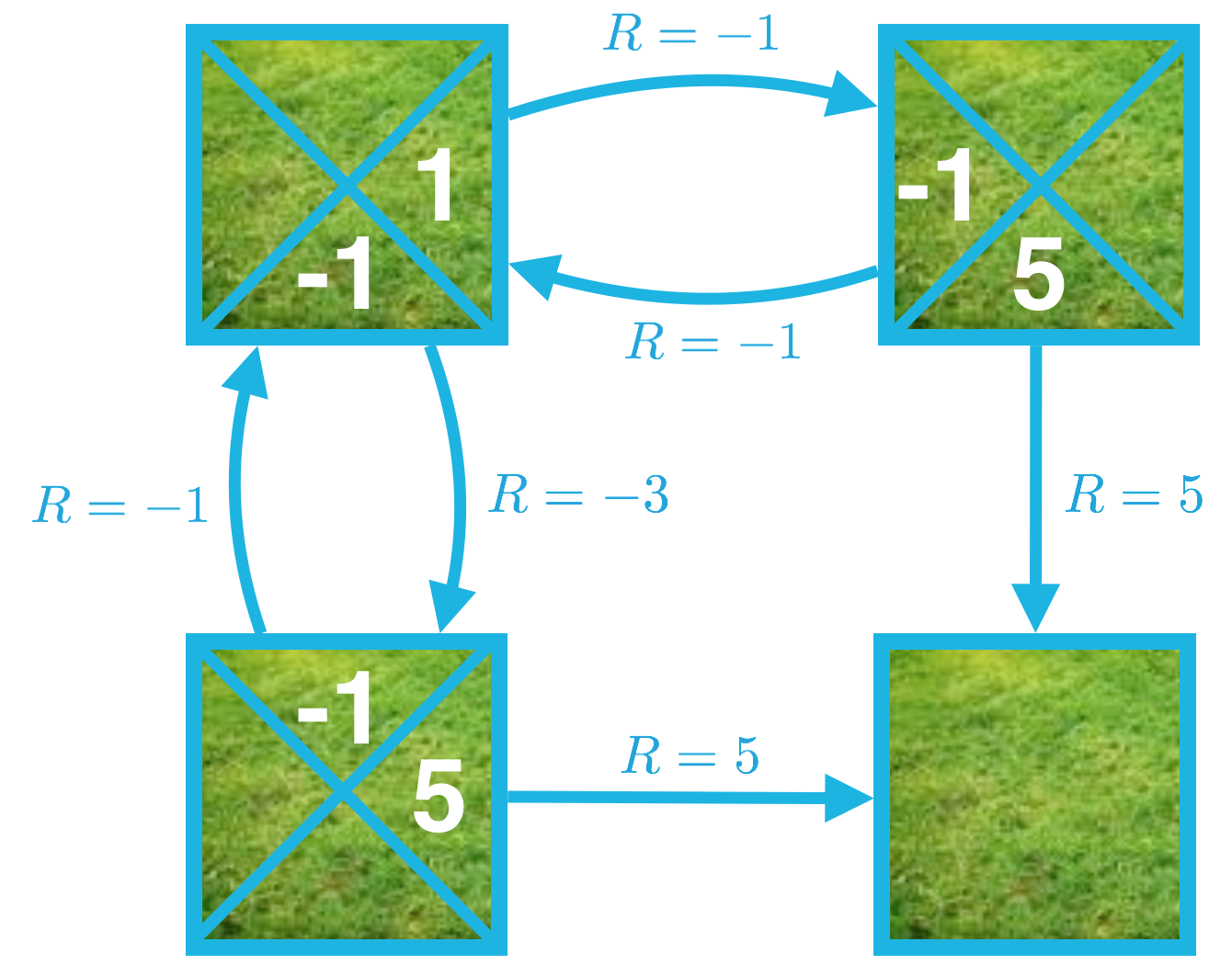
思考下 q_\pi(s_1, \text{right}) 这个示例。这个动作值的计算方式如下所示:
q_\pi(s_1, \text{right}) = -1 + v_\pi(s_2) = -1 + 2 = 1,
我们可以将状态动作对的值 s_1, \text{right} 表示为以下两个量的和:(1)向右移动并进入状态 s_2 的即时奖励,以及 (2) 智能体从状态 s_2 开始并遵守该策略获得的累积奖励。
现在请使用状态值函数 v_\pi 计算 q_\pi(s_1, \text{down})、q_\pi(s_2, \text{left})、q_\pi(s_2, \text{down})、q_\pi(s_3, \text{up}) 以及 q_\pi(s_3, \text{right})。
对于更加复杂的环境
在这个简单的网格世界示例中,环境是确定性环境。换句话说,智能体选择某个动作后,下个状态和奖励可以 100% 确定不是随机的。对于确定性环境,所有的 s', r, s, a 为 p(s',r|s,a) \in { 0,1 }。
在这种情况下,当智能体处在状态 s 并采取动作 a 时,下个状态 s' 和奖励 r 可以确切地预测,我们必须确保 q_\pi(s,a) = r + \gamma v_\pi(s')。
通常,环境并非必须是确定性环境,可以是随机性的。这是迷你项目中的 FrozenLake 环境的默认行为;在这种情况下,智能体选择动作后,下个状态和奖励无法确切地预测,而是从(条件性)概率分布 p(s',r|s,a)中随机抽取的。
在这种情况下,当智能体处在状态 s 并采取动作 a 时,每个潜在下个状态 s' 的概率和奖励 r 由 p(s',r|s,a) 确定。在这种情况下,我们必须确保 q_\pi(s,a) = \sum_{s'\in\mathcal{S}^+, r\in\mathcal{R}}p(s',r|s,a)(r+\gamma v_\pi(s')),我们计算和 r + \gamma v_\pi(s') 的期望值。
在接下来的几个部分,你将使用该方程为 FrozenLake 环境编写一个函数,并生成策略 \pi 对应的动作值函数 q_\pi。